快速开始 ¶
在线体验 ¶
| 访问地址 | 密码 | 账号 |
|---|---|---|
| http://www.sqlpara.com:9123/ | sqlpara | sqlpara |
部署 ¶
准备运行配置 ¶
安装docker环境,并下载镜像:https://download.docker.com/linux/centos/7/x86_64/stable/Packages/
安装docker-compose环境,命令:yum install -y docker-compose.noarch
启动 ¶
下载配置文件https://github.com/Dinosaur-Park/SQLPara,解压后进入docker-compose文件。按照以下操作步骤进行安装配置:
#修改密码和CRSF_TRUSTED_ORIGINS
数据库和Redis密码在.env文件和docker-compose.xml文件中均需修改
CRSF_TRUSTED_ORGINS在.env文件中修改
#启动
docker-compose -f docker-compose.yml up -d
#表结构初始化
docker exec -ti sqlpara /bin/bash
source /opt/venv4archery/bin/activate
python3 manage.py makemigrations sql
python3 manage.py migrate
#数据初始化
python3 manage.py dbshell<sql/fixtures/auth_group.sql
python3 manage.py dbshell<src/init_sql/mysql_slow_query_review.sql
#创建管理用户
python3 manage.py createsuperuser
#重启服务
docker restart sqlpara
#日志查看和问题排查
docker logs sqlpara -f --tail=10
logs/sqlpara.log
访问地址 ¶
http://$IP:9123/
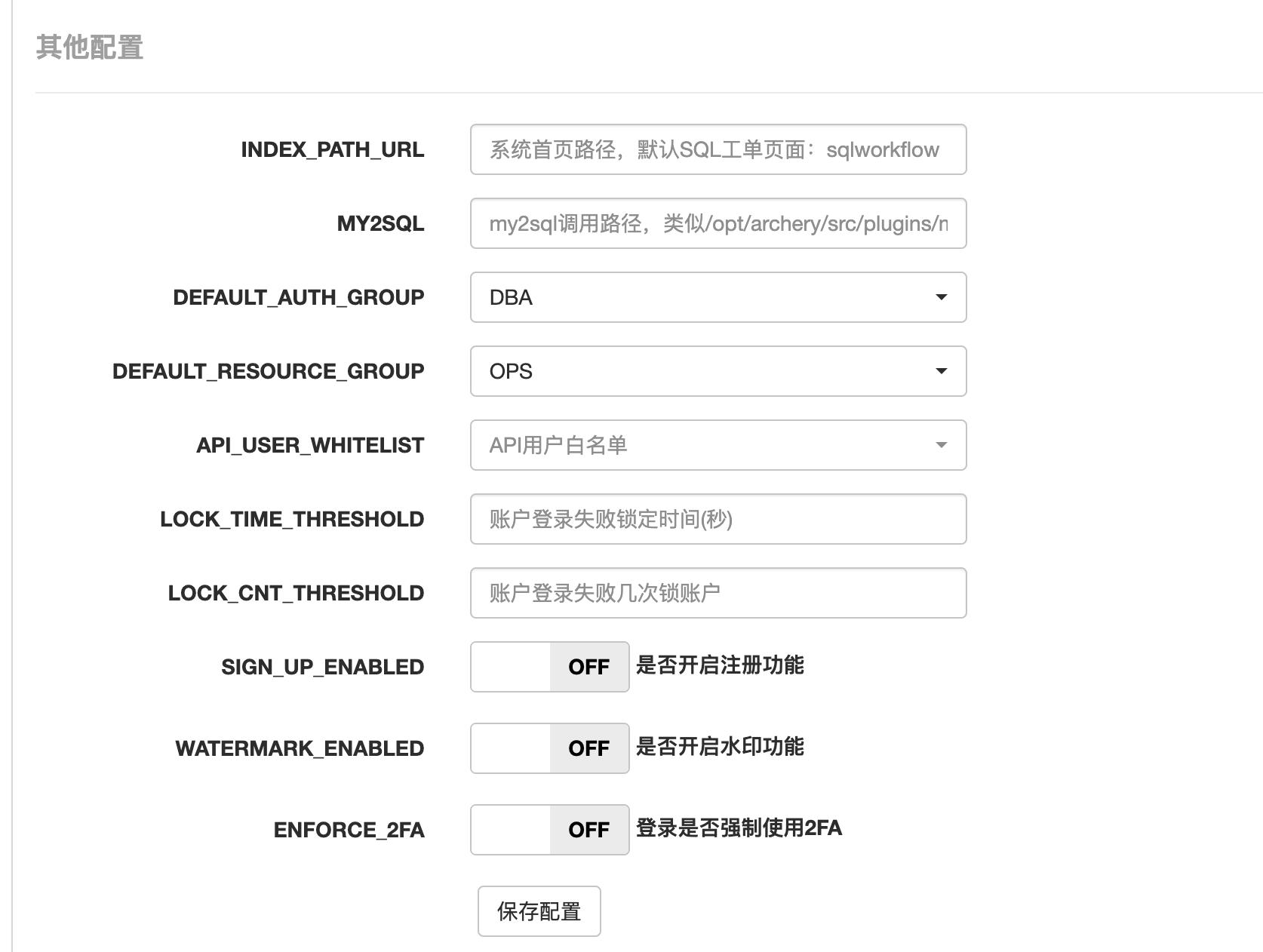
基础配置 ¶
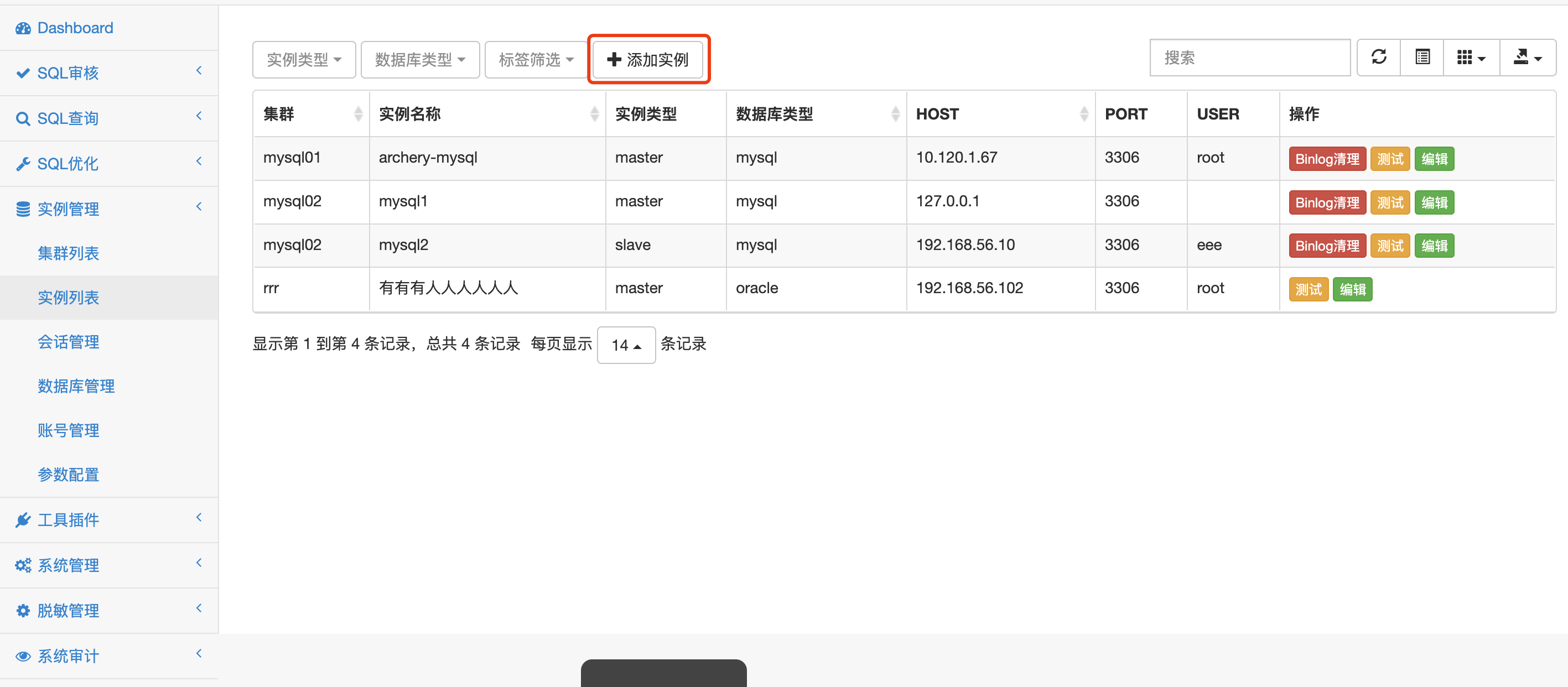
添加实例 ¶
- 实例类型分为主库/从库,支持的数据库类型为MySQL/MsSQL/Redis/PostgreSQL/Oracle/MongoDB/Phoenix/ODPS/ClickHouse,功能支持明细可查看功能清单
- 资源组:实例都需要关联资源组,才能被关联资源组的用户访问。以资源组为聚合数据库实例的节点,进行实例与用户的关联
- 实例标签:通过支持上线、支持查询的标签来控制实例是否在SQL上线/查询中显示,要使用上线和查询的实例需要关联标签
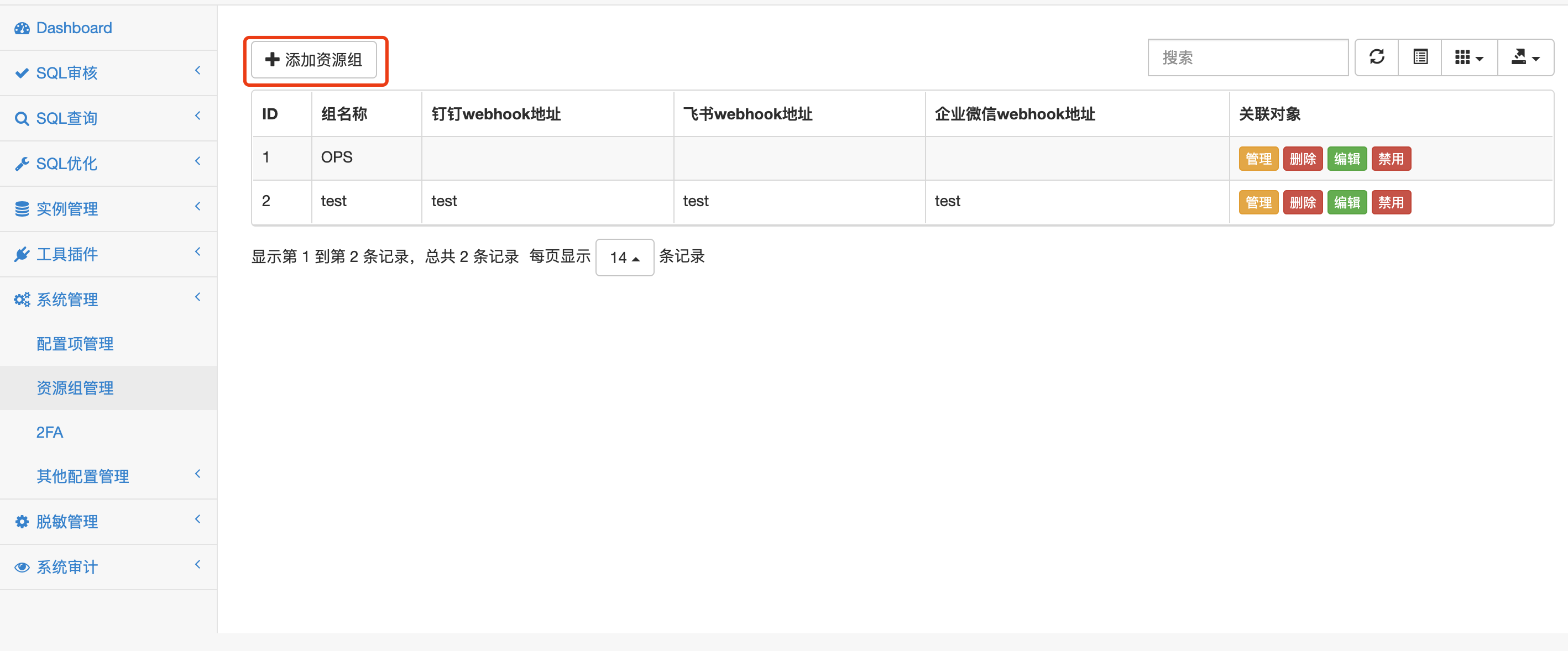
添加资源组 ¶
资源组是一堆数据库实例资源对象的集合,与用户关联后可以隔离资源访问权限。一般可以按照项目组划分
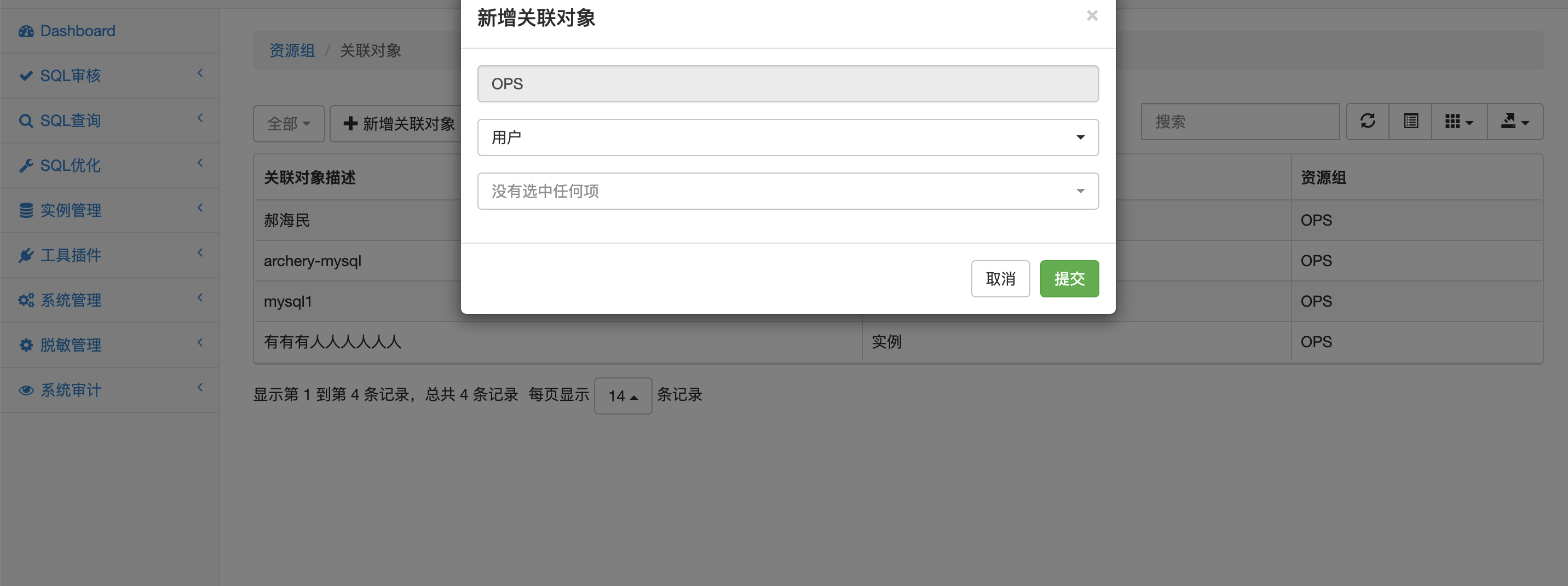
资源组关联用户/实例 ¶
用户必须关联资源组才能访问资源组内的实例资源 - 关联对象管理可以批量关联实例和用户 - 在添加用户和实例的时候也可以批量关联资源组
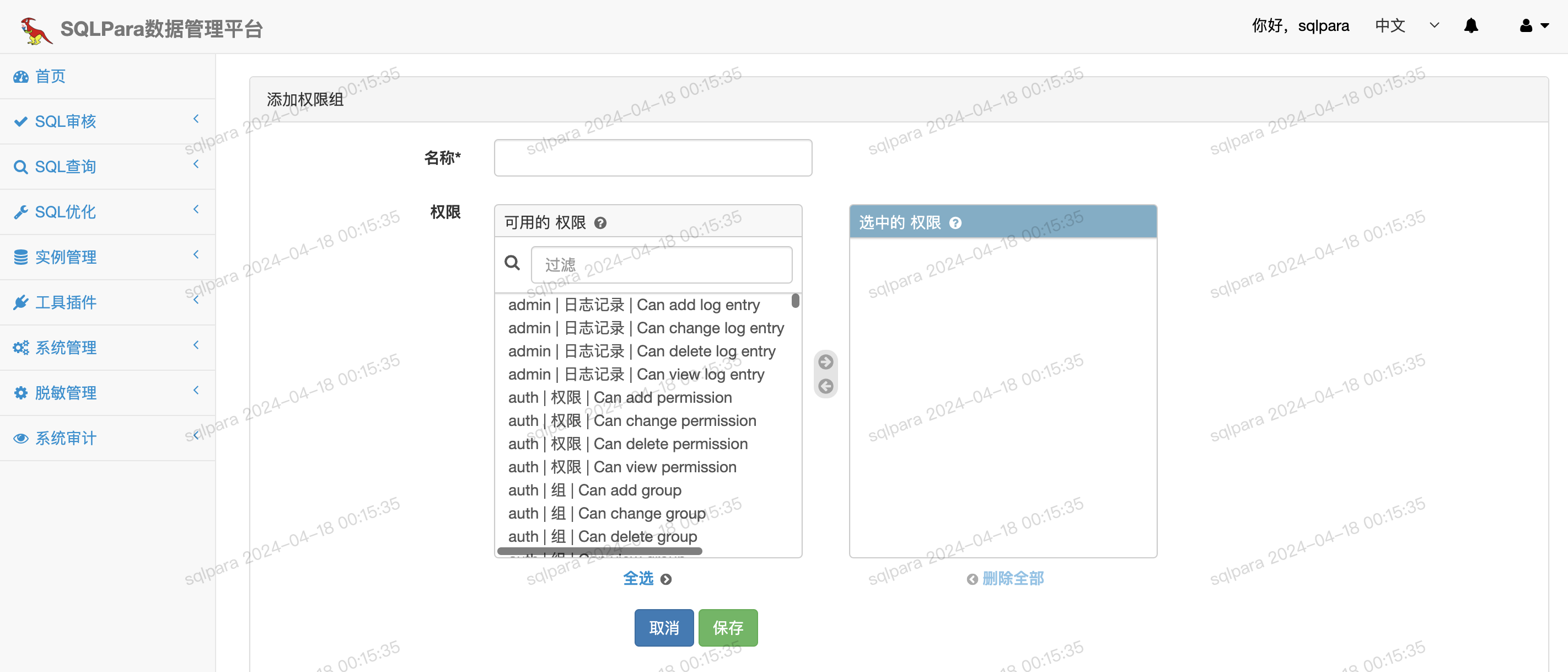
添加权限组 ¶
权限组是一堆权限的集合,类似于角色的概念,工作流的审批配置就是配置的权限组 - 权限组可以按照角色来创建,比如DBA、工程师、项目经理,目前系统初始化数据中会提供五个默认权限组,也可自由分配权限 - 仅[sql|permission]开头的权限是控制业务操作的权限,例如查询权限、上线权限等。其他都是控制系统管理后台的权限,例如管理员菜单系统管理、系统审计等,与业务无关
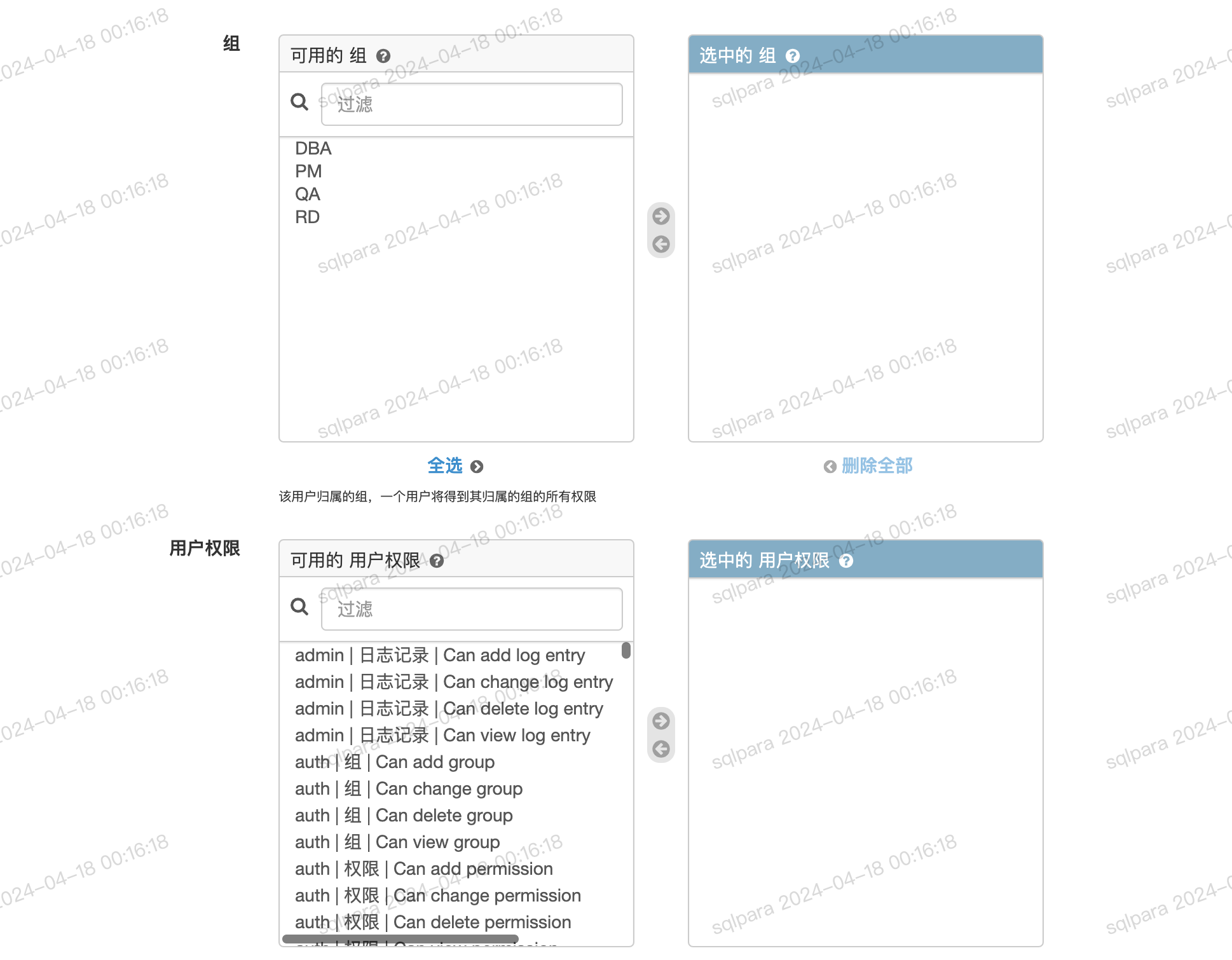
用户关联权限组/权限 ¶
用户所拥有的权限=用户所在权限组的权限+给用户单独分配的权限,其中用户单独分配的权限优先级更高
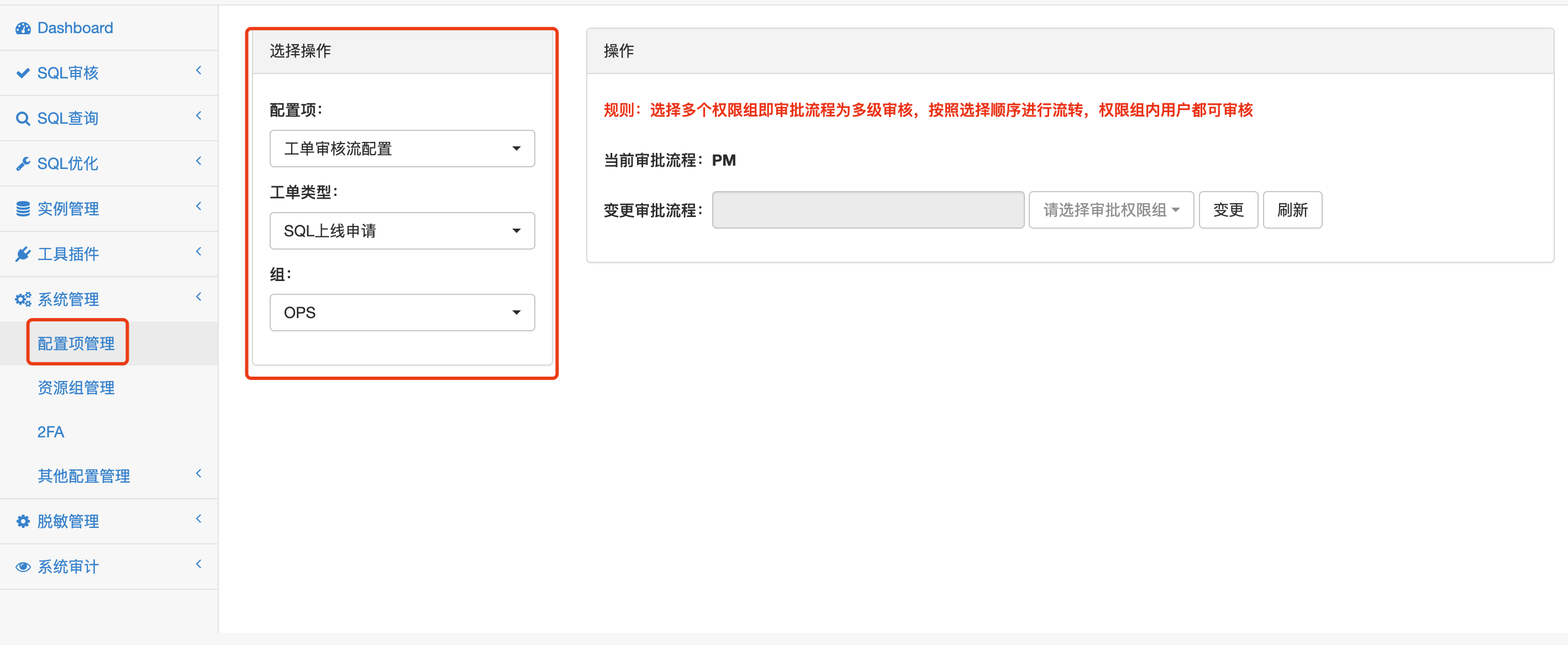
设置SQL上线、数据归档和查询权限(包括下载权限)的审批流程 ¶
系统提供简单的多级审批流配置,审批流程与资源组、审批类型相关,不同资源组和审批类型可以配置不同的审批流程,审批流程配置审批人是权限组,可避免发生审批人单点问题
设置默认资源组和默认权限组 ¶
可在系统配置中进行修改,详见 功能介绍
设置默认资源组和默认权限组,当新用户第一次登录时会自动进行关联,可避免用户登录后出现403(未授权)的问题,体验友好